· Jesse Edwards · Case Studies · 6 min read
How I Chose the Deployment and Component Architecture for RenovationRoute
Here's why I chose restraint over hype and how to save money early on.
RenovationRoute was built to solve real problems: unclear scopes, payment disputes, and broken trust between homeowners and contractors.
What architecture delivers clarity and accountability without creating new problems?
People love hype, teams jump straight to microservices, Kubernetes, blockchain or whatever is trending. I am not trying to write assembly, but I am also not trying to deal with something unstable, overly complex, and expensive. Sometimes new tech helps, most of the time, it adds cost, operational drag, and failure modes the business didn’t need yet. It is good for teams that have resources (time, money, people) to learn and try to apply that tech in the future when it will have a net positive outcome. I have been around long enough to know the right architecture for whatever the business challenge is.
For RenovationRoute, I chose the basic proven tech over hype. Not because I can’t build complex systems, but because production software that handles money needs to be boring, predictable, and correct. The other major factor was cost. When you are bleeding $250 every month just on servers, yikes. This is a very small shop at the moment, not like the companies I worked for where dropping thousands a month on a cloud provider is minuscule. As much as I love working on engineering, unfortunately a startup is not only engineering. Solving the tech problem is easy, getting people to know about it is the real challenge.
This post explains the principles behind those decisions and how early stage products with low resources can avoid higher cost and over engineering. It also paints a broader picture to help others understand behind the scenes.
Guiding Principles
Before writing code, I set a few rules:
Clarity first: One canonical source of truth. No duplicated data. No background sync jobs to keep systems aligned.
Restraint over novelty: Complexity is added only when real scale or requirements force it.
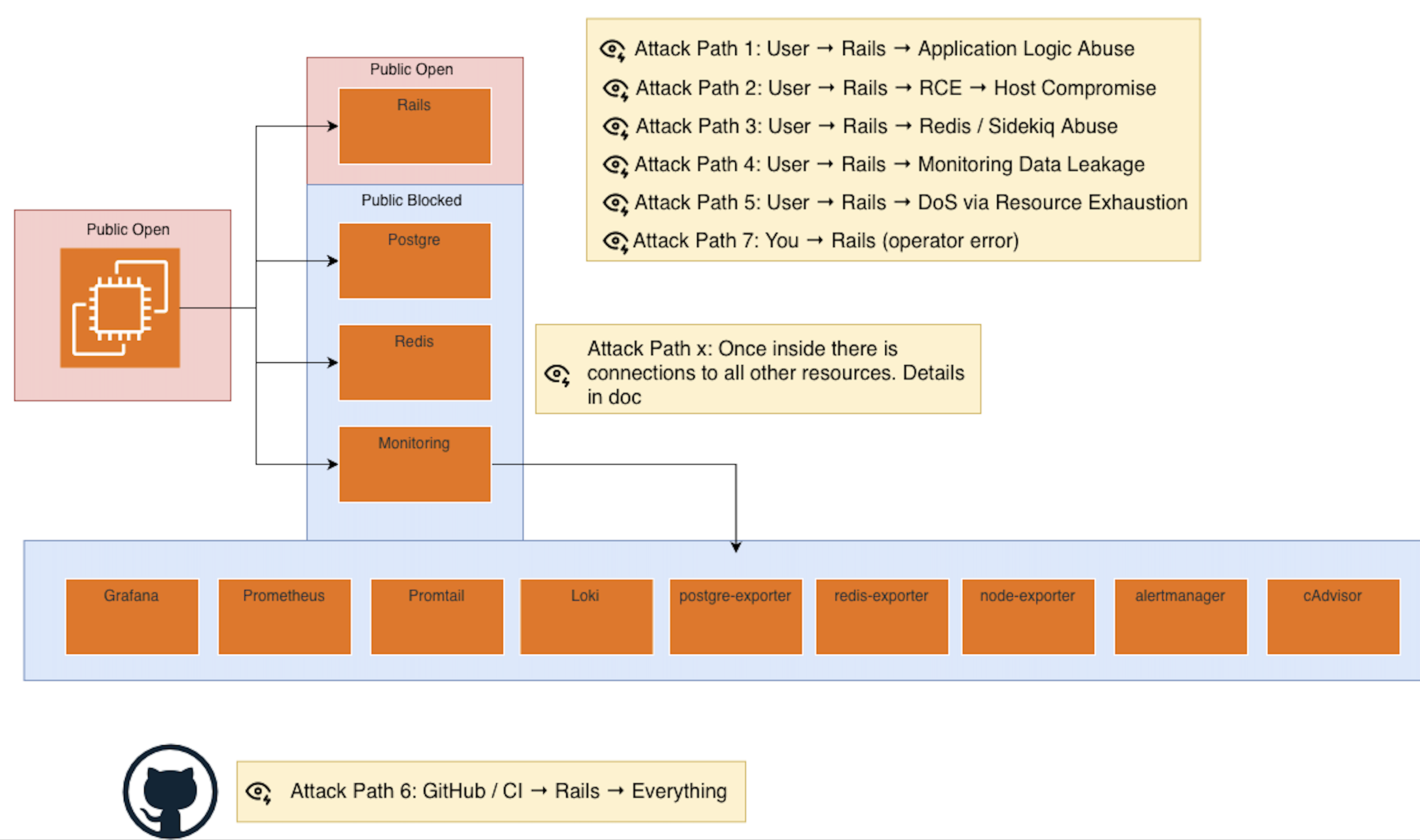
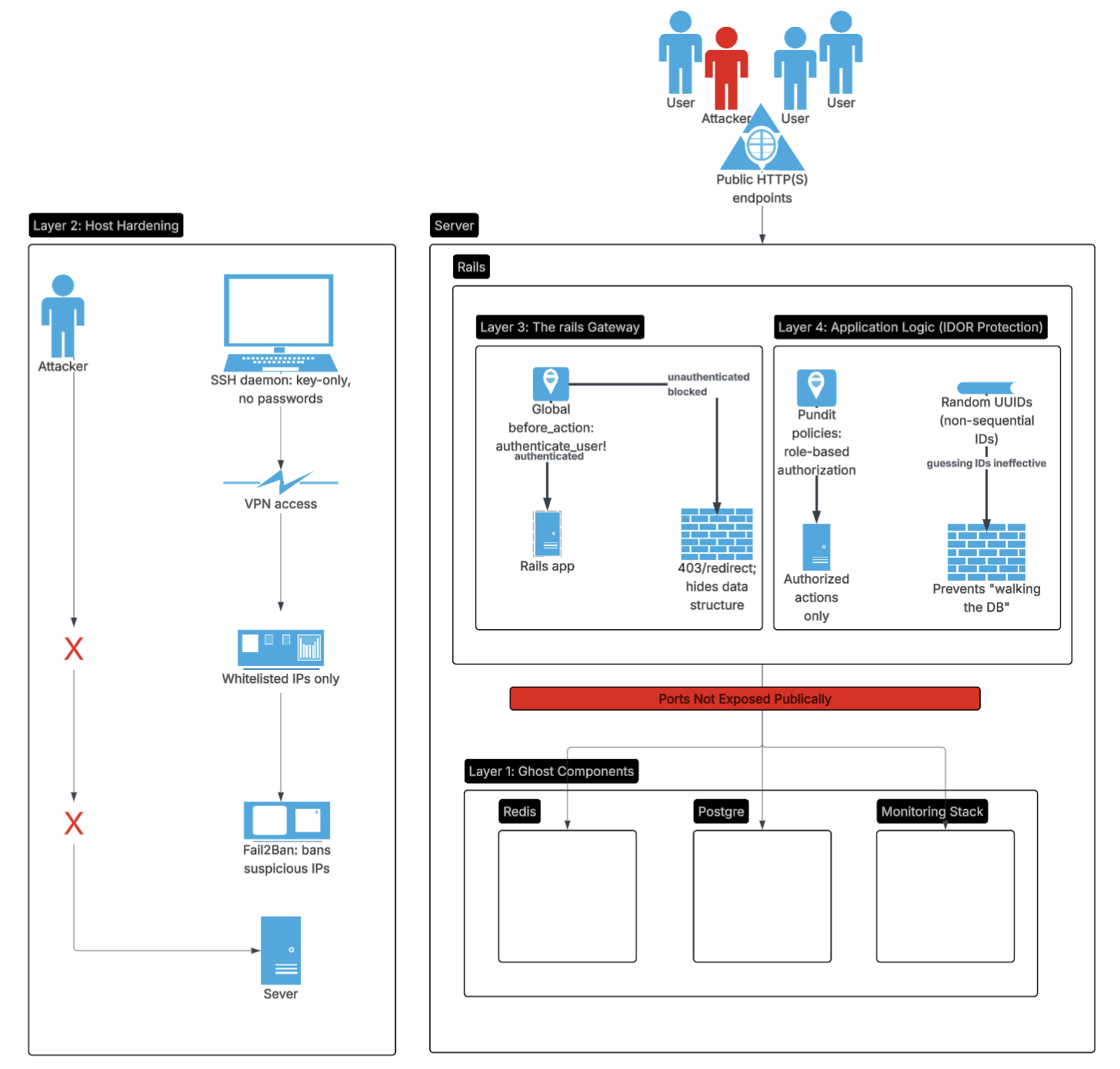
Security by default: Defense in depth from day one: From networking, to resource architecture, to programming.
Speed to value: Fast deploys, low operational overhead, and minimal moving parts.
The options
Some businesses fit neatly inside a boxed platform like Shopify. You trade flexibility for speed and accept a revenue cut in exchange for operational simplicity. Drop shippers, bloggers, and small e-commerce shops thrive here.
RenovationRoute doesn’t fit inside that. It requires custom workflows, escrow logic, project lifecycle tracking, and deep domain behavior. That puts it firmly in “custom application” territory.
Alright so now what are the options? Let’s start with the obvious.
A monolith gives:
- one deploy
- one database
- one failure domain
- one mental model
The core problem fits into a monolith well. The add ons later would be event driven, will save this for a later post.
Hosting and Deployment Tradeoffs
There are multiple ways to deploy a Rails application:
Opinionated PaaS (Heroku, Render, Railway): Fast to start, expensive at scale.
Container platforms without Kubernetes (Fly.io, Dokku): Flexible, still abstracted.
Rails automation (Cloud 66)
Modern DIY: Kamal (formerly MRSK) on EC2
Full platform engineering: Kubernetes (overkill early)
I’ve run systems across embedded environments, cloud platforms, and regulated production stacks. I could have chosen any of these. Again, the deciding factors weren’t technical skill they were; cost, control, and complexity.
I needed something reliable that wouldn’t bleed cash every month while I try to get customers to understand how to keep their moneies protected on their next renovation.
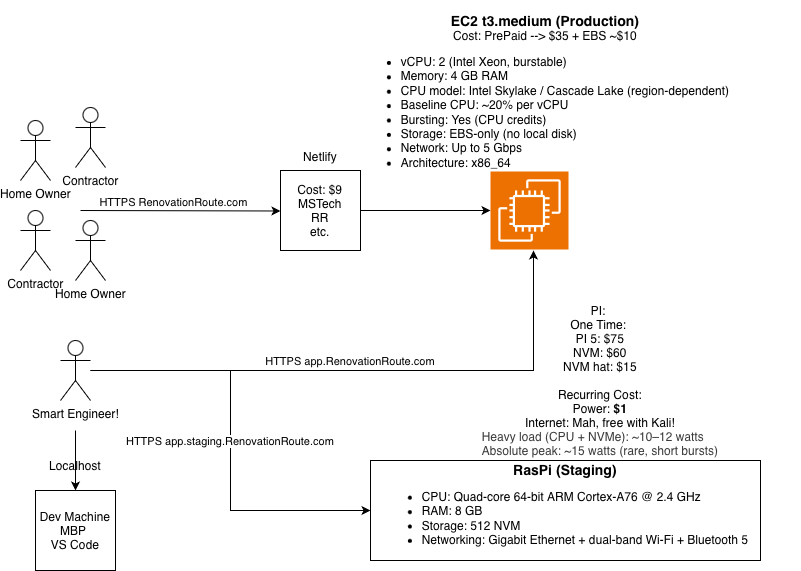
What would you pick? Don’t forget about the staging server! For those of you not familiar normally you have 3 environments. A local development, a staging server that mimics production, and the production server.
After a close call, the winner is… Reserved EC2 + Kamal! I would trade a day or two setting up the CI/CD pipeline to save $40-$100 every month. Startups transition through phases, getting them off the ground is like lifting the world. Every dollar is like having more air to breathe.
At every step there are tradeoffs. A good engineer will lay those out clearly and pick the right option. Again for me, speed/time, and cost. The platform is up, it is stable, and it is only costing me ~$35.
| Setup | Approx. Monthly Cost |
|---|---|
| Single EC2 + Kamal (current) | ~$35 |
| ECS (minimal, ALB + 2 nodes) | ~$90-150 |
| EKS (minimal, control plane + nodes) | ~$170-250+ |
| Premium PaaS (Heroku / Render / Railway) | ~$100+ |
Initial Scale (Where We Started)
Setup:
- 1x t3.medium EC2
- Rails app + PostgreSQL + Redis
- Background work offloaded
Because blocking operations are pushed into background jobs, the web tier stays responsive. Homeowners are light users. Contractors spike usage during quoting, then drop off.
That usage pattern matters.
Lets talk about what we can get out of this setup.
Observed capacity (directional estimates):
| Setup | Concurrent Requests | Active Users | Total Users |
|---|---|---|---|
| Single instance | 24-32 | 300-400 | 1,500-2,000 |
This is inexpensive, reliable, and easy to operate.
Monitoring and alerting, not guesses, determine when it’s time to scale.
First Scale Step
Split responsibilities:
- Separate PostgreSQL and Redis
- Keep web tier stateless
| Setup | Concurrent | Active Users | Total Users |
|---|---|---|---|
| 2x t3.medium | 50-60 | 600-800 | 3,000-4,000 |
At this point, you’ve doubled capacity without introducing architectural risk.
Horizontal Scaling and High Availability
Next steps are still boring and that’s good:
- Managed RDS (Multi-AZ)
- Managed ElastiCache
- Two web servers
- Application Load Balancer
This comfortably reaches 8,000-10,000 users.
Adding a third web server behind the ALB pushes capacity to 12,000-15,000 users.
Past ~20k users, you reassess:
- larger instances
- more web nodes
- or selective service extraction
No rewrite required.
Here are some rough numbers and options for 12-36 months out. In the background, I would consider starting to build a Kubernetes solution so we could switch over if needed.
Stage 1: Squeeze the Monolith (20k-50k users)
Before adding services, remove pressure.
- Read replicas (writes → primary, reads → replicas)
- Aggressive caching (fragment + HTML)
- CDN in front (CloudFront)
- Background job isolation
- Connection pooling (PgBouncer)
This alone can carry a Rails app to 50k-100k users if traffic patterns are sane.
Stage 2: Fault Isolation Without Fragmentation (50k-100k)
Still a monolith just smarter.
- Auto Scaling Groups
- Separate worker fleet
- Dedicated Redis clusters
- Queue backpressure controls
- Feature flags to kill hot paths instantly
Web servers become disposable. Deploys become boring. Failures are localized.
This is where most startups should stop.
Stage 3: The First Real Split (Pain-Driven Only)
You don’t “go FULL microservices. tropic thunder!”
You extract one thing.
Good candidates:
- File processing
- Search
- Notifications
- AI workloads
- External integrations
The monolith remains the system of record. New services communicate asynchronously and scale independently.
This is a hybrid architecture, not microservices chaos.
Stage 4: Data Is the Hard Problem
At real scale, data hurts before compute.
- Table partitioning
- Read/write separation
- Time-based sharding
- Tenant isolation
Most teams fail here by splitting services before fixing data access patterns.
Final Thoughts
The message here, if you are a startup or early stage product, start simple. You can push these basic architectures pretty far.
If you are a midsize company or have a product that you can see scaling fast, obviously skip this. It is like trying to hit a dartboard. Try to hit the bullseye every time. I would not advise this route for everyone, but for a slow growing startup it made sense.
If I would have picked Kubernetes, say AWS EKS, my bill would have been $170-$300/mo just throwing money away since I am not even close to getting that many users onboarded yet.
The goal isn’t to build for a million users on day one.
The goal is to survive long enough to earn that complexity.
Most startups fail long before scale becomes their problem. This architecture is designed to make sure RenovationRoute isn’t one of them.
The first post were about the business requirements. This post covered startup the component architecture for low revenue / low customer. Upcoming posts will discuss selecting a framework, system/component architecture security for mid or even enterprise, internal architecture, observability, CI/CD and more.